DoNews5月5日消息,曾几何时,谷歌一度被业界认定为 AI 行业的领先者,其2017 年率先发布 Transformer 奠定了 大语言模型 LLM 的基石,2021 年聊天机器人 LaMDA 的亮相更是一度惊艳圈内。
不曾想,最终抢得先机的却是 OpenAI 这匹“黑马”,而谷歌反倒从 AI 领域的“老大哥”沦为了被动的“追赶者”。究竟谁会最终赢得这场 AI 大战,是谷歌还是OpenAI?
近来在 Discord 群组由匿名人士泄露的一份谷歌内部文件给出了第三个可能:“我们没有赢得这场竞争,OpenAI 也没有。当我们还在争吵时,第三个方已经悄悄地抢了我们的饭碗——开源。”
据CSDN报道,开源正在超越谷歌和 OpenAI,这两家所认为的“主要开放问题”如今已经解决,并已投入使用。虽然两家的模型当下在质量方面仍略胜一筹,但差距正在惊人地缩小。开源模型更快、更可定制、更私密,能力也更强大。
开源能用 100 美元和 13B 参数做到谷歌和 OpenAI 花费 1000 万美元和 540B 参数都难以达成的事情。而且只需要几周就能完成任务,而不是几个月。
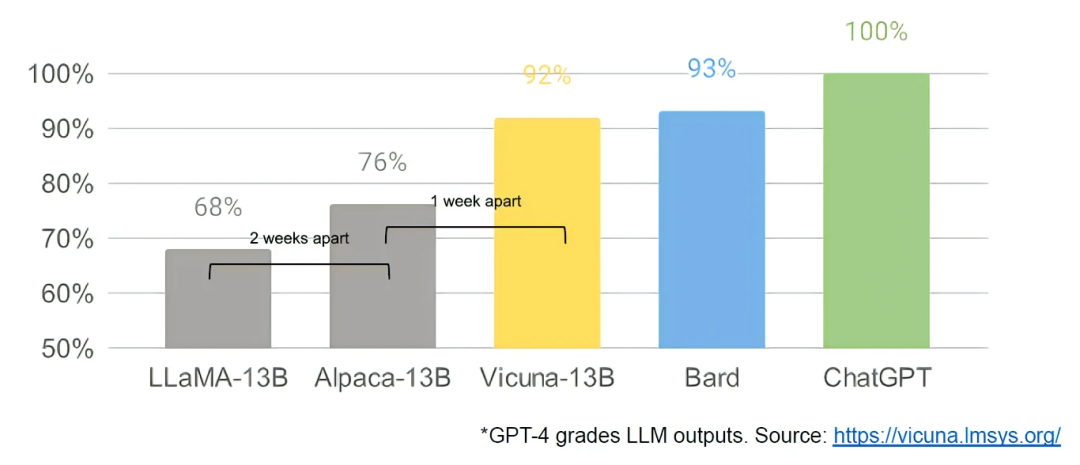
当免费、无限制的替代品在质量上相当时,人们不会为一个受限制的模式付费。谷歌应该考虑自己的附加值究竟在哪里。
从长远来看,最好的模型是可以快速迭代改进的模型。现在,既然知道了 20B 参数范围内可能实现什么,小变体就不应再被视为事后补救措施了。
3月初,开源社区得到了他们的第一个真正有能力的基础模型——Meta 的 LLaMA 模型被意外泄露了。它没有指令或对话调整,也没有 RLHF (人类反馈强化学习)。
随后,巨大的创新涌现出来,在短短不到一个月的时间里,已经出现了具备指令调整、量化、质量改进、人类评估、多模态和 RLHF 等变体,其中许多都是相互建立的。
最重要的是,开源社区解决了扩展问题,在一定程度上任何人都可以进行实验。许多新想法来自普通人,培训和实验门槛从主要研究机构总产出降至一个人、一个晚上和一台强大的笔记本电脑。
据了解,目前开源 LLM 的复兴是紧随图像生成的复兴而来的,许多人称其为 LLM 的“Stable Diffusion(开源文本生成图像模型) 时刻”。
在两种情况下,低成本公共参与得以实现,原因是有了名为低秩适应(LoRA)的大幅度降价机制,并结合规模上的重大突破。在这两种情况下,获得足够高质量模型启动了世界各地个人和机构涌现出一系列想法和迭代。
这些贡献在图像生成领域非常关键,使 Stable Diffusion 走上了与 Dall-E (OpenAI基于Transformer的语言模型,可根据文本生成图像)不同的道路,使其拥有一个开放的模式,导致了产品整合、市场、用户界面和创新,而这些都是 Dall-E 没有的。
其效果可想而知:文化影响力迅速占据主导地位,OpenAI 解决方案变得越来越无关紧要。同样的事情是否会发生在 LLM 上还有待观察,但广泛的结构元素是相同的。
LoRA 更新非常便宜(约 100 美元),这意味着几乎任何有想法的人都可以生成并分发一个。训练时间少于一天是正常的,在这种速度下,所有这些微调的累积效应不需要很长时间就可以克服开始时的劣势。
事实上,就工程师时间而言,这些模型的改进速度远远超过了谷歌所能做到的,而且最好的模型已经与 ChatGPT 基本没有区别了。专注于维护全球一些最大规模的模型实际上会使谷歌处于不利地位。
对此,得克萨斯大学奥斯汀分校教授Alex Dimakis认为,开源 AI 正在取得胜利,对于全世界来说这是件好事,对于构建一个有竞争力的生态系统来说也是好事。
文章来源:DoNews
本站声明:网站内容来源于网络,如有侵权,请联系我们,我们将及时处理。
标签:ChatGPT